In this post I will explain how to go about rotating or translating images.
Scaling
Scaling can be done by using the cv2.resize() function.The size can be provided manually or a scaling factor can be given.
import cv2
import numpy as np
img = cv2.imread('image.jpg')
height, width = img.shape[:2]
res = cv2.resize(img,(2*width, 2*height), interpolation = cv2.INTER_CUBIC)
cv2.imshow('img',res)
cv2.waitKey(0)
cv2.destroyAllWindows()
The interpolation method used here is cv2.INTER_CUBIC
The default interpolation function is cv2.INTER_LINEAR
Translation
Shifting any objects location can be done using the cv2.warpAffine
To shift an image by (x,y) a transformation matrix M =[(1,0,Tx),(0,1,Ty)] using numpy array type np.float32. The following example code shifts the image by (200,100).
import cv2
import numpy as np
img = cv2.imread('image.jpg',0)
rows,cols = img.shape
M = np.float32([[1,0,100],[0,1,50]])
dst = cv2.warpAffine(img,M,(cols,rows))
cv2.imshow('img',dst)
cv2.waitKey(0)
cv2.destroyAllWindows()
This results into:

The cv2.warpAffine function takes in three arguments. The first is the image. Second is the transformation matrix for shifting. And the third is the output size.
Rotation
OpenCV provides rotation with an adjustable center of rotation and a scaling factor. The transformation matrix for rotation M is:
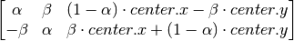
Where:
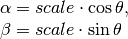
import numpy as np
import cv2
img = cv2.imread('image.jpg',0)
rows,cols = img.shape
M = cv2.getRotationMatrix2D((cols/2,rows/2),90,1)
dst = cv2.warpAffine(img,M,(cols,rows))
cv2.imshow('image',dst)
cv2.waitKey(0) & 0xFF
cv2.destroyAllWindows()
To apply this transformation matrix we used the OpenCV function cv2.getRotationMatrix2D. We scale the image by half and rotate it by 90 degrees anticlockwise.
The result is:
Affine Transformation
In this transformation all the parallel lines are kept parallel in the final image.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('image.jpg')
rows,cols,ch = img.shape
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[10,100],[200,50],[100,250]])
M = cv2.getAffineTransform(pts1,pts2)
dst = cv2.warpAffine(img,M,(cols,rows))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
cv2.imshow('image',dst)
cv2.waitKey(0) & 0xFF
cv2.destroyAllWindows()
To obtain the transformation matrix we need three points from the source image and three points of the destination image to define the planes of transformation. Then using the function cv2.getAffineTransform we get a 2×3 matrix which we pass into the cv2.warpAffine function.
The result looks like this:

Perspective Transform
This transformation leads to change in the point of view of the image. The straight lines remain as it is. For this transformation we need 4 points from the source and output image of which 3 should be non-collinear to define a plane. From these points we define a 3×3 matrix using cv2.getPerspectiveTransform and pass the resulting matrix into cv2.warpPerspective.
import numpy as np
import cv2
from matplotlib import pyplot as plt
img = cv2.imread('image.jpg')
rows,cols,ch = img.shape
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[0,0],[300,0],[0,300],[300,300]])
M = cv2.getPerspectiveTransform(pts1,pts2)
dst = cv2.warpPerspective(img,M,(300,300))
plt.subplot(121),plt.imshow(img),plt.title('Input')
plt.subplot(122),plt.imshow(dst),plt.title('Output')
plt.show()
plt.show()
cv2.imshow('image',dst)
cv2.waitKey(0) & 0xFF
cv2.imwrite('result.png',dst)
cv2.destroyAllWindows()
The result looks like this :

Thats all !!


















